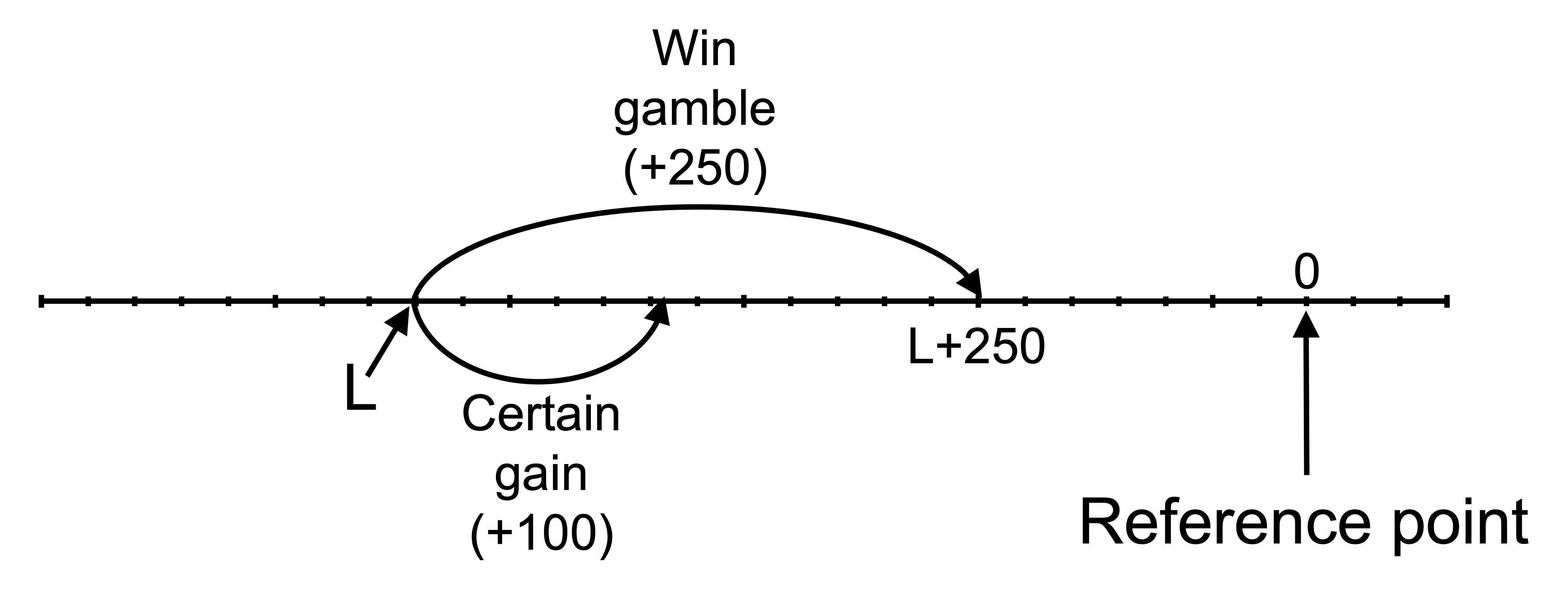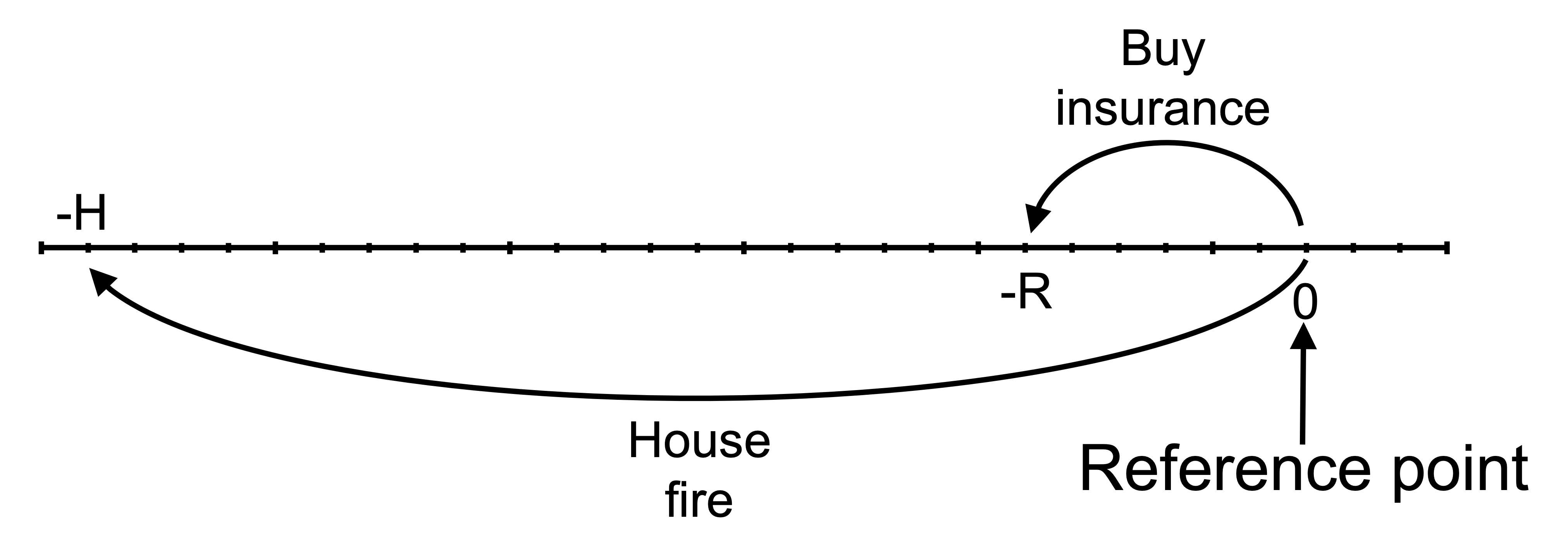In the following mathematical examples, I demonstrate the operation of prospect theory through various scenarios, illustrating how individuals make decisions under uncertainty based on reference points, loss aversion, and diminishing sensitivity to gains and losses.
The 50:50 gamble demonstrates loss aversion, with losses weighted more heavily than equivalent gains.
The 60:40 gamble shows how diminishing sensitivity and loss aversion interact to influence decision-making.
The gamble in the gain domain illustrates the reflection effect, where individuals are risk-averse for gains but become risk-seeking for losses.
Changes in wealth or reference points can significantly alter risk preferences, as shown in the examples of accepting or rejecting gambles after losses or wins.
In this section, I present a series of mathematical examples of prospect theory.
18.1.1 A 50:50 gamble
Suppose Alby has the following reference-dependent value function:
v(x)=\left\{\begin{matrix}
x^\frac{1}{2} \qquad &\textrm{where} \space x \geq 0\\[6pt]
-2(-x)^\frac{1}{2} \quad &\textrm{where} \space x < 0
\end{matrix}\right.
x is the realised outcome relative to the reference point.
Assume that Alby’s reference point is the status quo and that he weights outcomes linearly.
Alby is offered the gamble A:
(0.5, \$110; 0.5, −\$100)
Accept or reject?
Will Alby want to play this gamble?
To determine this, we compare the weighted value of the gamble with the weighted value of rejecting the offer.
Alby will not want to play this gamble as it has a negative value. He could receive a weighted value of 0 by simply not playing.
The reason for this negative value is that Alby is loss averse. The loss of $100 is given twice the weight of an equivalent gain.
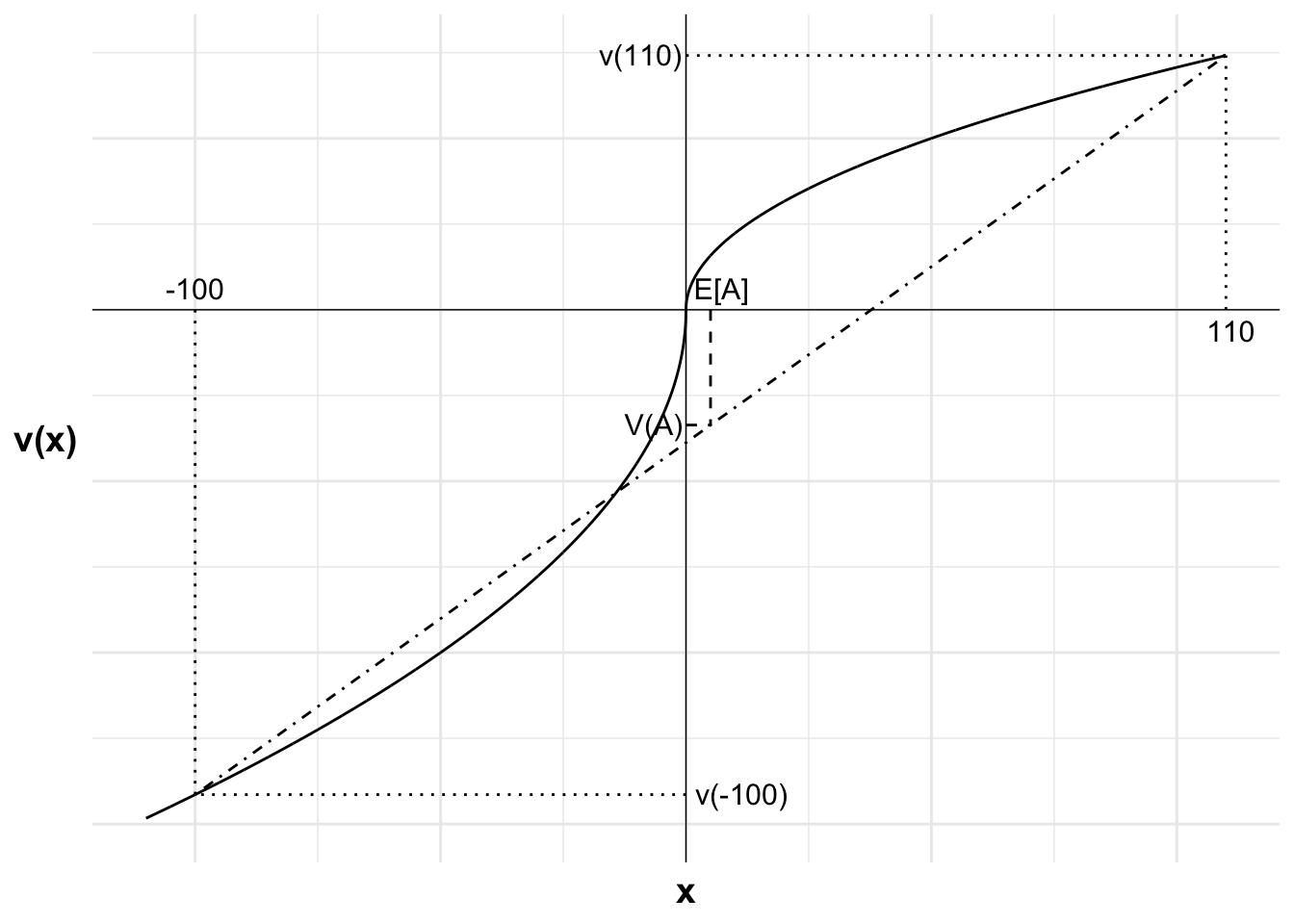
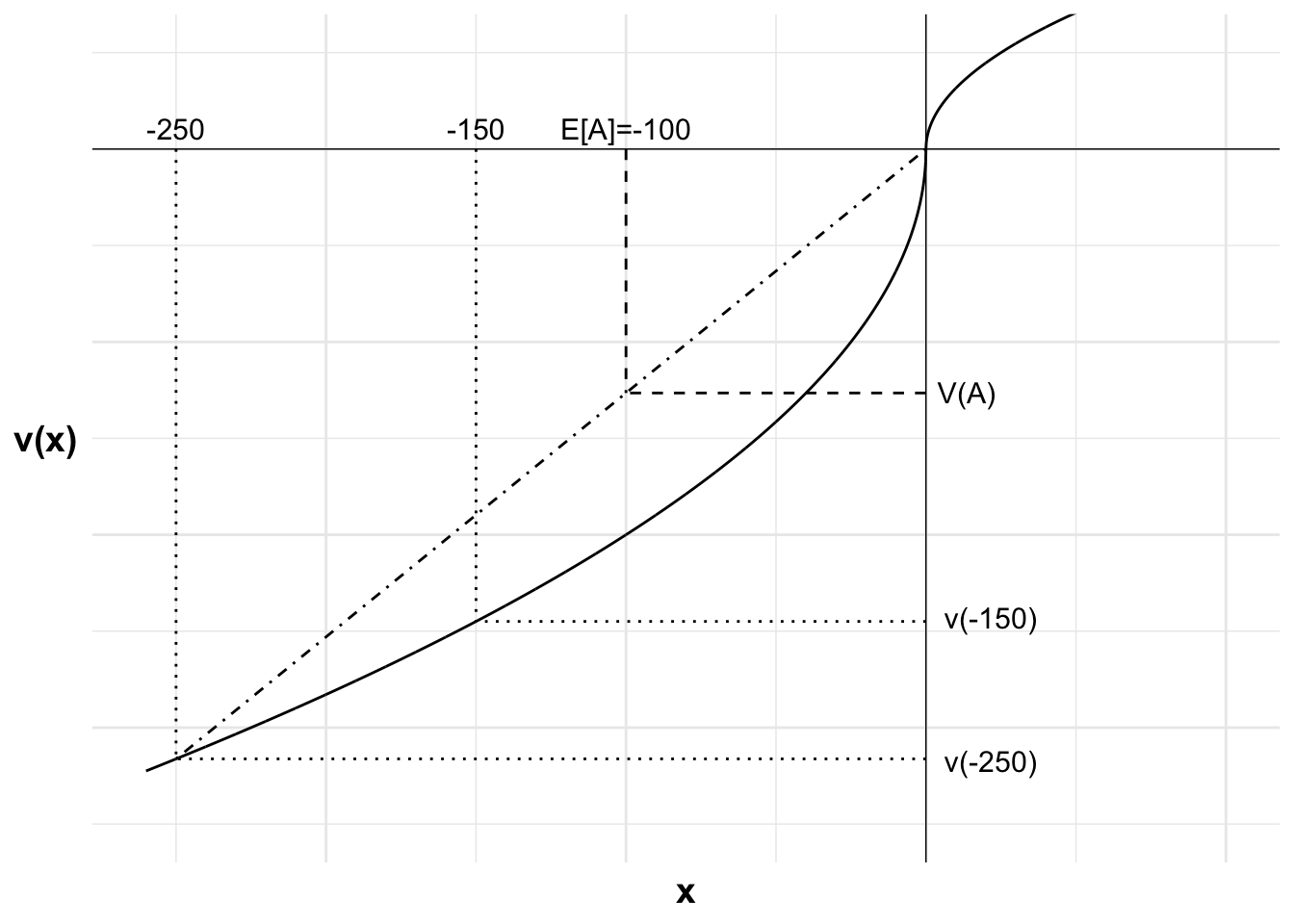
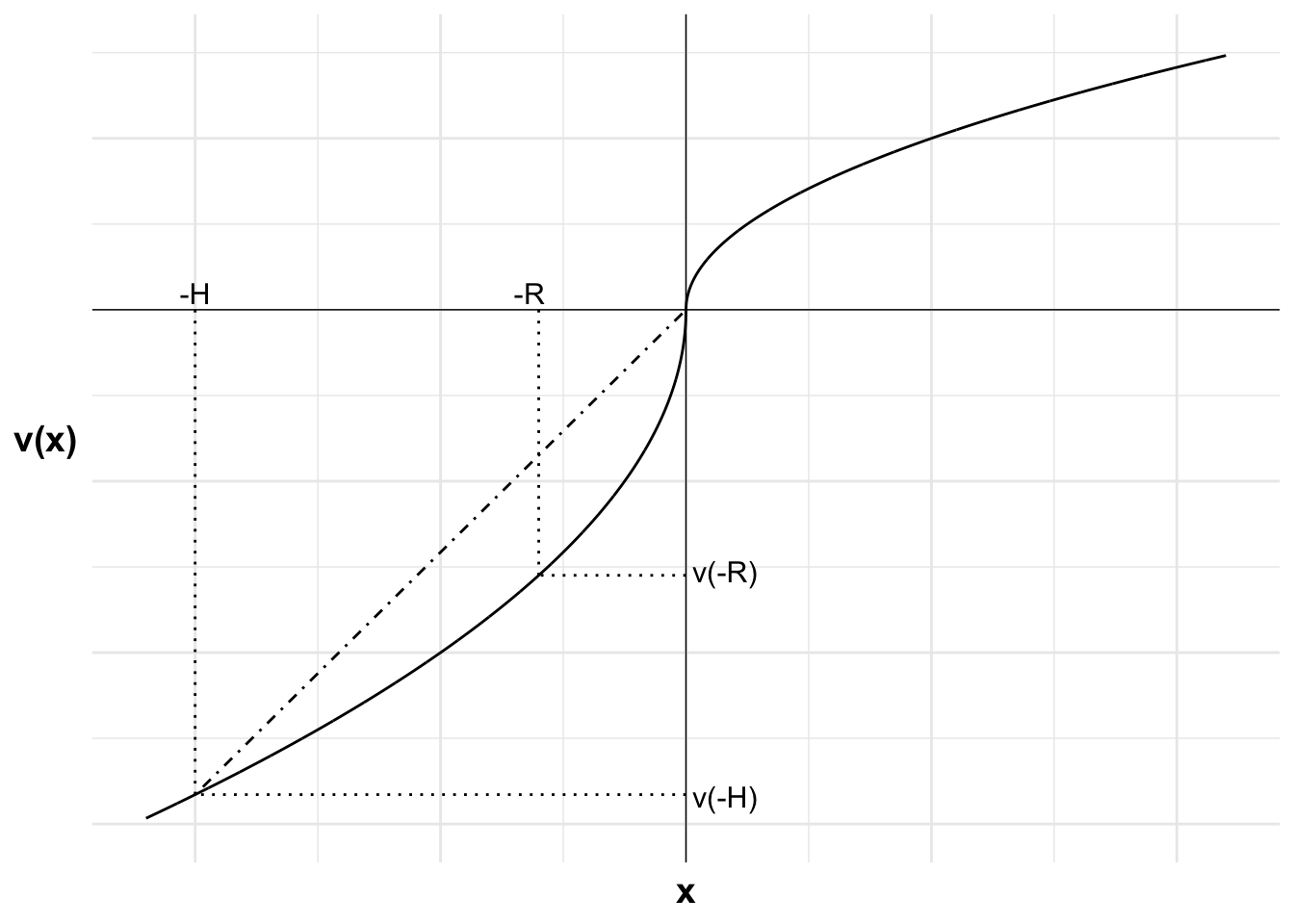
The following chart illustrates. The horizontal axis is the outcome x relative to the reference point. The vertical axis is the value of each outcome. The S-shaped curve represents Alby’s value function, with a concave curve in the game domain and a convex curve in the loss domain. The curve is steeper in the loss domain, due to loss aversion.
The gain of $110 and the loss of $100 and their respective values are marked.
I have drawn a straight line between the two outcomes. The weighted value of the two outcomes will be on this line.
As the probability of each outcome is 50 percent, the expected value of A, $5, is halfway between the two outcomes. If we project to the straight line from the expected value, we get V(A), a probability-weighted average of the two possible outcomes from the bet. V(A) is negative, indicating that the gamble has a lower weighted value than remaining at the status quo.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1 <--200#lossx2 <-220#winev <-10#expected value of gamblexc <-0#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))+#Add labels -100, v(-100) and line to curve indicating eachannotate("text", x = x1, y =0, label ="-100", size =4, hjust =0.5, vjust =-0.5)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(-100)", size =4, hjust =-0.1, vjust =0.45)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")+#Add labels 110, v(110) and line to curve indicating eachannotate("text", x = x2, y =0, label ="110", size =4, hjust =0.4, vjust =1.5)+annotate("segment", x = x2, y =0, xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x2), xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x2), label ="v(110)", size =4, hjust =1.05, vjust =0.45)+#Add labels E[A], V(A) and curve indicating eachannotate("text", x = ev, y =0, label ="E[A]", size =4, hjust =0.3, vjust =-0.5)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label ="V(A)", size =4, hjust =1.05, vjust =0.45)
Figure 18.1: A 50:50 gamble
Accept or reject after loss?
Suppose Alby loses his wallet containing $100. He feels bad about it and perceives it as a loss. His reference point is unchanged at the original status quo, but the amount of money he will have after any outcome is $100 less than otherwise. Would he be willing to take gamble A now?
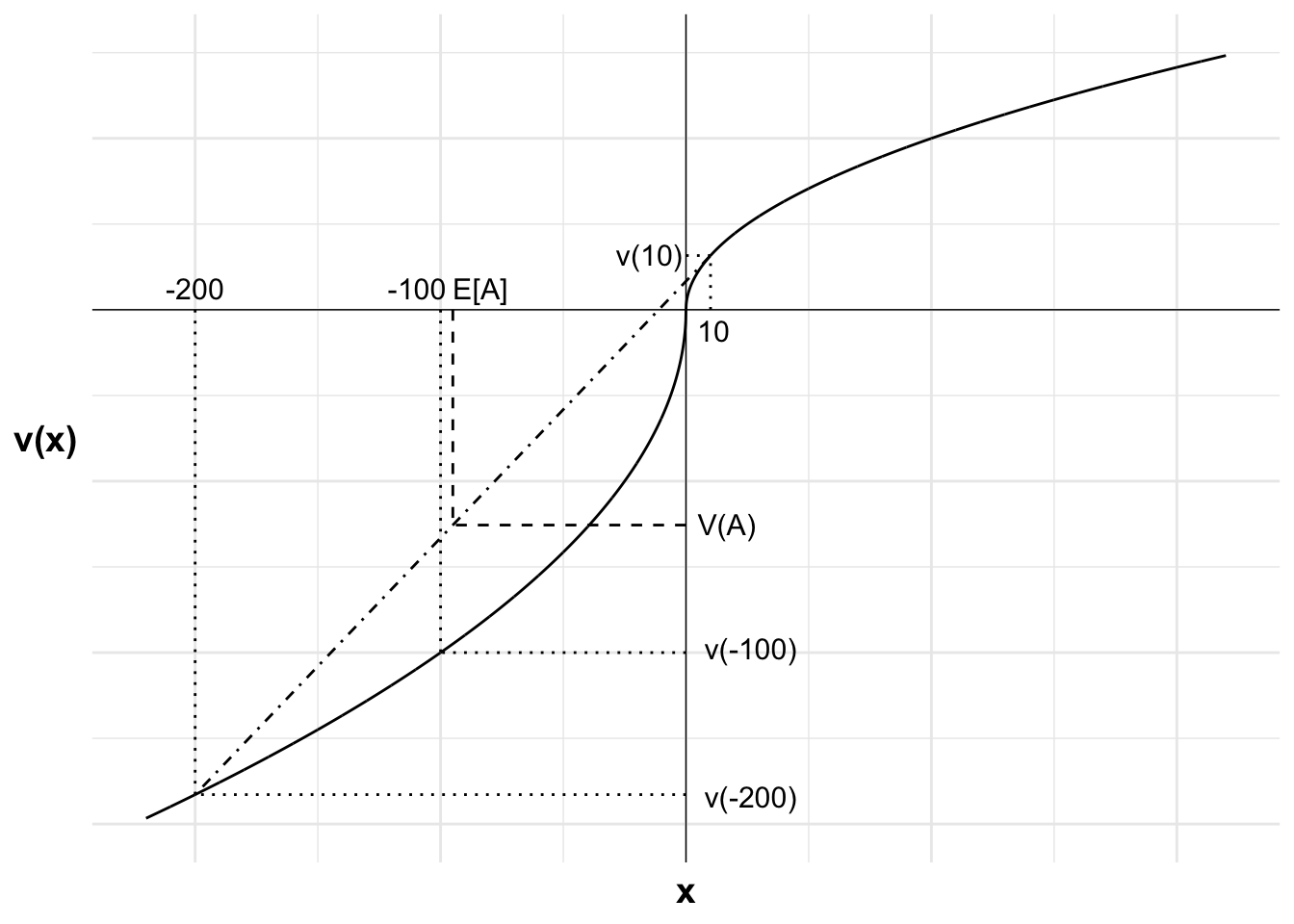
After losing $100 but not changing his reference point, he has two possible outcomes relative to his reference point: a gain of $10 (winning $110 minus the lost money in the wallet) and a loss of $200 (losing $100 and also losing his wallet).
He will now want to play the gamble as it has a greater value than staying with his current loss. The gamble becomes attractive as it allows recovery of the loss. Alby is risk seeking in the loss domain. (He would even accept a 50:50 gamble to win or lose $100 with an expected value of zero.)
The choice is illustrated in the following chart. The two possible outcomes, $200 below the reference point and $10 above the reference point, plus their values, are marked. The weighted value of those two possible outcomes is also marked, with the expected value, E of A, projected onto the line between the two outcomes to give V(A)
It is visually apparent that V(A) is above the value of a loss of $100, the outcome if Alby does not accept the gamble. As a result, Alby wants to accept the gamble.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1 <--200#lossx2 <-10#winev <--95#expected value of gamblexc <--100#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))+#Add labels -200, v(-200) and line to curve indicating eachannotate("text", x = x1, y =0, label ="-200", size =4, hjust =0.5, vjust =-0.5)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(-200)", size =4, hjust =-0.2, vjust =0.6)+#Add labels -100, v(-100) and line to curve indicating eachannotate("text", x = xc, y =0, label ="-100", size =4, hjust =0.9, vjust =-0.5)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="v(-100)", size =4, hjust =-0.2, vjust =0.3)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")+#Add labels 10, v(10) and line to curve indicating eachannotate("text", x = x2, y =0, label ="10", size =4, hjust =0.4, vjust =1.5)+annotate("segment", x = x2, y =0, xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x2), xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x2), label ="v(10)", size =4, hjust =1.05, vjust =0.45)+#Add labels E[A], V(A) and curve indicating eachannotate("text", x = ev, y =0, label ="E[A]", size =4, hjust =0, vjust =-0.5)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label ="V(A)", size =4, hjust =-0.2, vjust =0.45)
Figure 18.2: A 50:50 gamble after a loss
Accept or reject after adaptation to loss?
Alby has now adapted to his loss of $100. The new reference point is the new wealth level incorporating the loss wallet. Would he take gamble A now?
We are now back to an identical situation as when he was first offered the gamble with his reference point as the status quo. He will not want to partake in the gamble.
Accept or reject after a win?
Alby wins $10,000 at the casino. He feels good about his win, so his reference point remains at his wealth excluding the win. Would he take gamble A now?
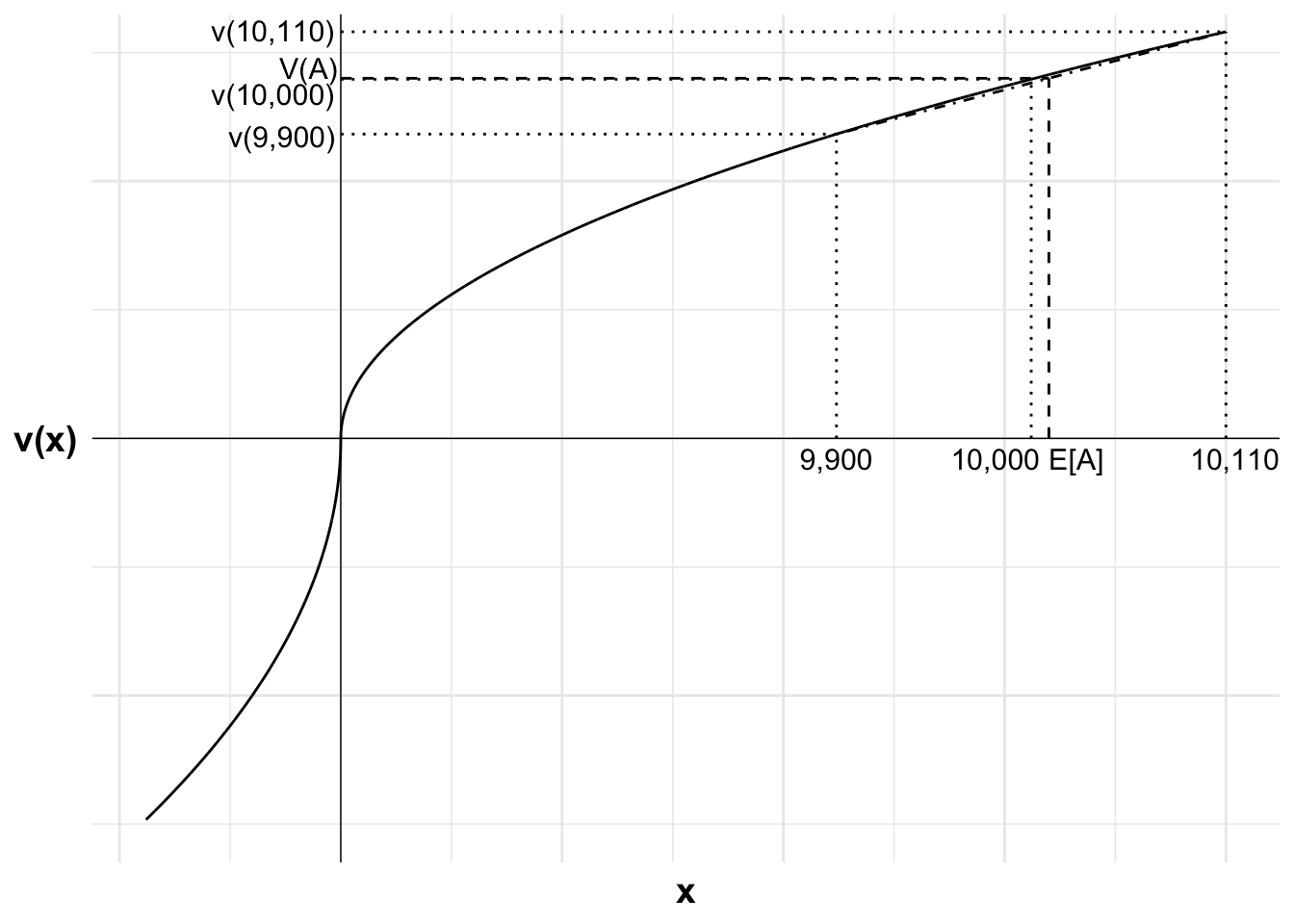
With the additional $10,000, the value of the gamble is:
The gamble is now attractive. Alby is less risk averse at a higher wealth. Further, the gamble is entirely in the gain domain, meaning that loss aversion does not affect the decision.
The following chart, not drawn to scale, illustrates. Alby becomes increasingly risk neutral as we move further into the gain domain. You can see this through the value function curve becoming approximately straight. As a result, at a high enough wealth, the positive value bet becomes attractive. V(A) is above the value of the certain outcome, V(10000).
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 1000, 0.1),y =u(seq(-220, 1000, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1 <-560#lossx2 <-1000#winev <-800#expected value of gamblexc <-780#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 1000), ylim =c(-30, 30))+#Add labels 9,900, v(9,900) and line to curve indicating eachannotate("text", x = x1, y =0, label ="9,900", size =4, hjust =0.5, vjust =1.5)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(9,900)", size =4, hjust =1.05, vjust =0.6)+#Add labels 10,000, v(10,000) and line to curve indicating eachannotate("text", x = xc, y =0, label ="10,000", size =4, hjust =0.9, vjust =1.5)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="v(10,000)", size =4, hjust =1.05, vjust =1.2)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")+#Add labels 10,110, v(10,110) and line to curve indicating eachannotate("text", x = x2, y =0, label ="10,110", size =4, hjust =0.4, vjust =1.5)+annotate("segment", x = x2, y =0, xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x2), xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x2), label ="v(10,110)", size =4, hjust =1.05, vjust =0.45)+#Add labels E[A], V(A) and curve indicating eachannotate("text", x = ev, y =0, label ="E[A]", size =4, hjust =0, vjust =1.5)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label ="V(A)", size =4, hjust =1.05, vjust =0)
Figure 18.3: A 50:50 gamble after a win (not to scale)
18.1.2 A 60:40 gamble
Paddy makes decisions in accordance with prospect theory, has wealth $300 and value function:
v(x)=\left\{\begin{matrix}
x^{\frac{1}{2}} \quad &\textrm{where} \quad x \geq 0 \\[6pt]
-2(-x)^{\frac{1}{2}} \quad &\textrm{where} \quad x < 0
\end{matrix}\right.
Assume Paddy weights probabilities linearly.
Paddy is offered the following bet A:
a 60% probability to win $150
a 40% probability to lose $100.
Accept or reject
Does Paddy accept bet A?
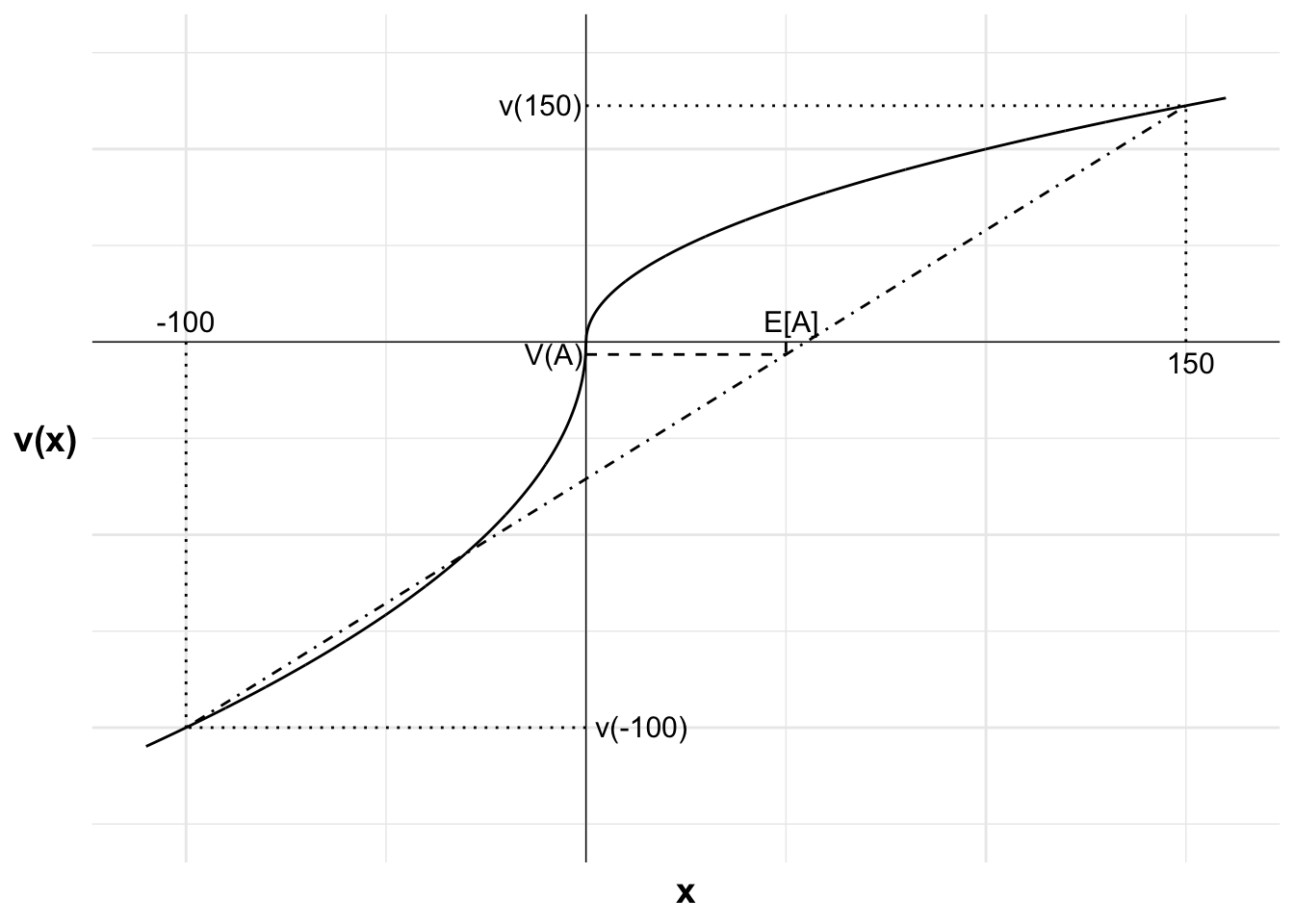
Paddy compares the value of taking versus not taking the bet:
The value of not taking the bet is zero. Paddy would have no change from his reference point.
Paddy rejects the bet as V(A) is less than the V(0)=0 that Paddy could get by simply rejecting the bet. He rejects the bet due to his loss aversion and diminishing sensitivity to gains. The loss is weighted double that of an equivalent gain, outweighing both the larger potential gain and 60% probability.
The following figure shows Paddy’s value function, the bets and the value of the bets. The figure illustrates that Paddy’s rejection is caused by both Paddy’s loss aversion and his diminishing sensitivity in the gain domain, which has a larger effect than the diminishing sensitivity in the loss domain due to the larger magnitude of the potential gain.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-110, 160, 0.1),y =u(seq(-110, 160, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1 <--100#lossx2 <-150#winev <-0.6*150-0.4*100#expected value of gamblexc <-0#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-110, 160), ylim =c(-25, 15))+#Add labels -100, v(-100) and line to curve indicating eachannotate("text", x = x1, y =0, label ="-100", size =4, hjust =0.5, vjust =-0.5)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(-100)", size =4, hjust =-0.1, vjust =0.45)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")+#Add labels 150, v(150) and line to curve indicating eachannotate("text", x = x2, y =0, label ="150", size =4, hjust =0.4, vjust =1.5)+annotate("segment", x = x2, y =0, xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x2), xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x2), label ="v(150)", size =4, hjust =1.05, vjust =0.45)+#Add labels E[A], V(A) and curve indicating eachannotate("text", x = ev, y =0, label ="E[A]", size =4, hjust =0.4, vjust =-0.5)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label ="V(A)", size =4, hjust =1.05, vjust =0.45)
Figure 18.4: A 60:40 gamble
Accept or reject after a loss?
Following some bad economic news, Paddy’s wealth declines to $150. Paddy cannot get over the loss, so his reference point remains his former wealth of $300.
Paddy is offered bet A again. Does Paddy accept the bet?
As Paddy is now in the loss domain, the two potential outcomes from the bet are a gain of $0 and a loss of $250. His alternative is remaining at a point $150 below his reference point.
Paddy compares the value of taking versus not taking the bet:
Paddy accepts the bet as V(A) is greater than the value of the certain loss of $150.
The following figure shows Paddy’s value function, the bets and the value of the bets. The figure shows that Paddy accepts the bet as he is risk seeking in the loss domain. The potential loss of another $100 results in a smaller incremental loss of value than an equivalent win of $100.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-260, 100, 0.1),y =u(seq(-260, 100, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1 <--250#lossx2 <-0#winev <--100#expected value of gamblexc <--150#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-260, 100), ylim =c(-35, 5))+#Add labels -250, v(-250) and line to curve indicating eachannotate("text", x = x1, y =0, label ="-250", size =4, hjust =0.5, vjust =-0.5)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(-250)", size =4, hjust =-0.2, vjust =0.6)+#Add labels -150, v(-150) and line to curve indicating eachannotate("text", x = xc, y =0, label ="-150", size =4, hjust =0.5, vjust =-0.5)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="v(-150)", size =4, hjust =-0.2, vjust =0.3)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")+#Add labels E[A]=-100, V(A) and curve indicating eachannotate("text", x = ev, y =0, label ="E[A]=-100", size =4, hjust =0.5, vjust =-0.5)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label ="V(A)", size =4, hjust =-0.2, vjust =0.45)
Figure 18.5: A 60:40 gamble after a loss
18.1.3 A gamble in the gain domain
Suppose Bill has the following reference-dependent value function:
v(x)=\left\{\begin{matrix}
x^{1/2} \qquad &\textrm{where} &\space x \geq 0\\
-2(-x)^{1/2} \quad &\textrm{where} &\space x < 0
\end{matrix}\right.
x is the change in Bill’s position relative to his reference point.
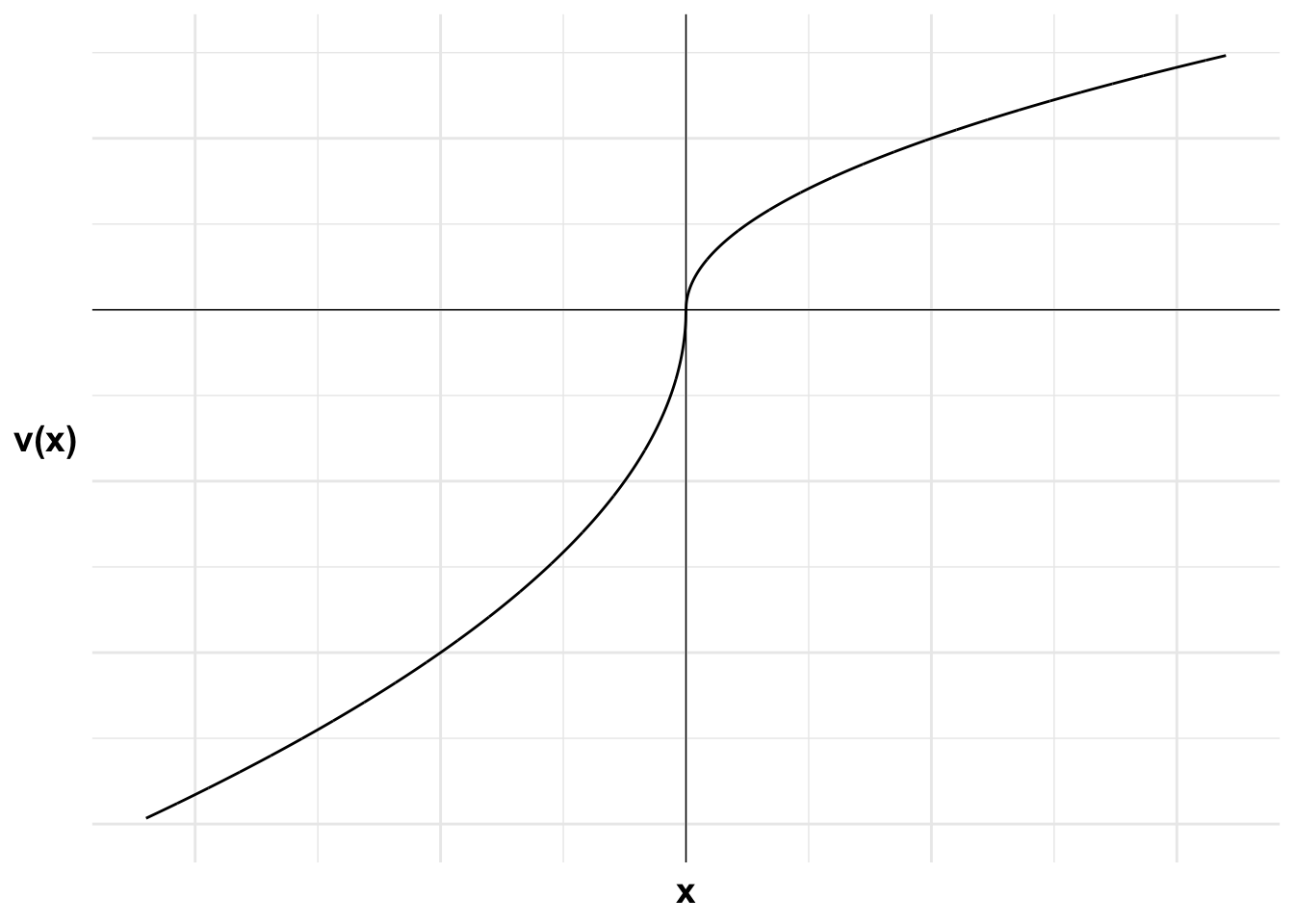
What feature of Bill’s value function leads to the reflection effect?
The power of \frac{1}{2} applied in both the gain and loss domain leads to diminishing sensitivity to gains and losses. The value function is concave in the gain domain and convex in the loss domain. This curvature leads to risk-averse behaviour in the gain domain and risk-seeking behaviour in the loss domain. This change in risk preference between the gain and loss domains is the reflection effect.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))
Figure 18.6: Bill’s value function
Accept or reject?
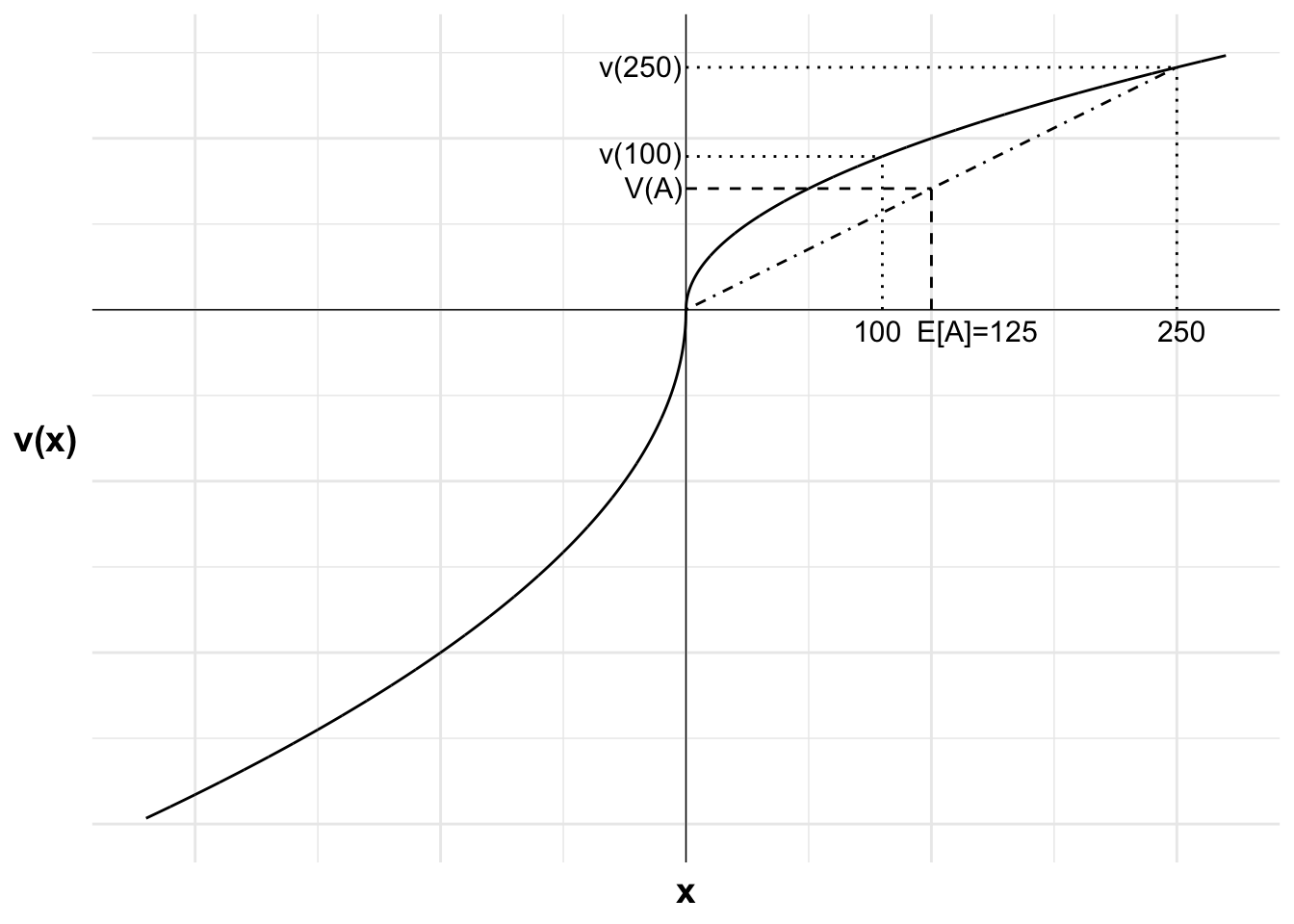
Bill considers a choice between $100 for certain and gamble A: (0.5, $250; 0.5, 0).
As V(\$100)>V(A), Bill will prefer the $100 for certain to the gamble.
The possible outcomes from the gamble are zero and $250. The certain outcome on offer is $100. The expected value of the gamble is $125. The outcomes are in the gain domain.
As he is risk averse in the gain domain, the value of the $100 for certain exceeds the weighted value of the gamble. This can be seen through v(A) being less than v(\$100). Bill will therefore choose the $100 for certain.
The following chart shows Bill’s choices. Bill rejects the gamble because of the diminishing sensitivity to gains. This leads him to be risk averse and reject the higher expected value option of the gamble.
As all possible outcomes under our assumed reference point are in the gain domain, loss aversion does not affect his decision. Note that we do not use the value function for x<0 in determining Bill’s choice.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<-0#lossx2<-200#winev<-100#expected value of gamblexc<-80#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))+#Add labels W+20, U(W+20) and line to curve indicating eachannotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+#Add labels 100, U(100) and line to curve indicating eachannotate("text", x = xc, y =0, label ="100", size =4, hjust =0.6, vjust =1.5)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="v(100)", size =4, hjust =1.05, vjust =0.3)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")+#Add labels 250, v(250) and line to curve indicating eachannotate("text", x = x2, y =0, label ="250", size =4, hjust =0.4, vjust =1.5)+annotate("segment", x = x2, y =0, xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x2), xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x2), label ="v(250)", size =4, hjust =1.05, vjust =0.45)+#Add labels E[A], V(A) and curve indicating eachannotate("text", x = ev, y =0, label ="E[A]=125", size =4, hjust =0.12, vjust =1.5)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label ="V(A)", size =4, hjust =1.05, vjust =0.45)
Figure 18.7: Bill’s consideration of gamble A and the $100
Accept or reject after a negative shock?
Suppose Bill were to experience a large negative shock to his wealth that does not immediately change his reference point. Could this shock cause him to change his decision concerning the $100 and gamble A?
A large negative shock to Bill’s wealth would cause him to change his decision concerning the $100 and gamble A. The shock would move the two possible outcomes into the loss domain, where Bill is risk seeking. (For this answer, I am assuming a shock of greater than $250. A smaller shock would change the analysis.)
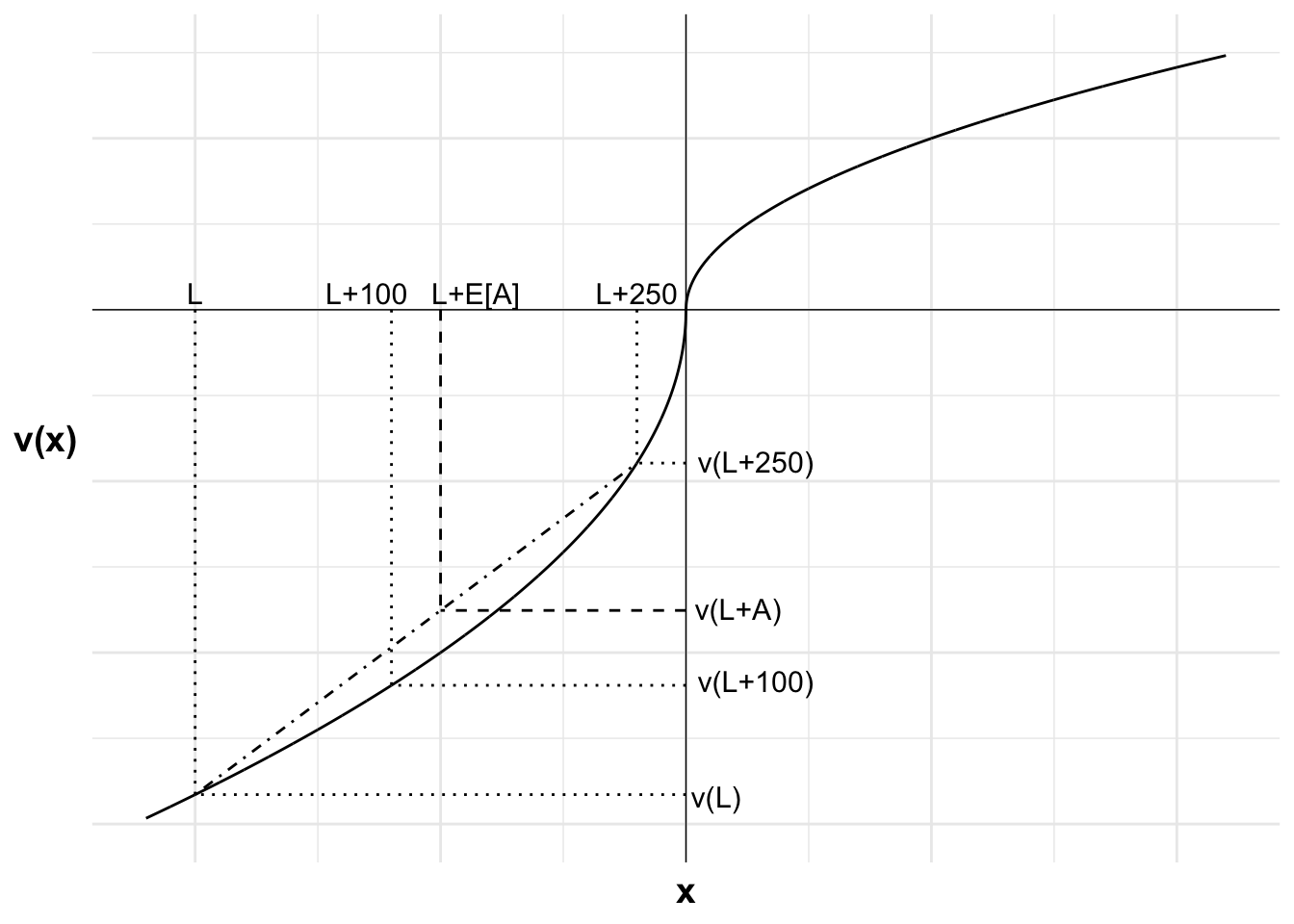
The following diagram illustrates the outcomes relative to the reference point. Let L be a large negative number, the loss. The potential outcomes from the gamble are now L and L+250. The certain outcome of accepting the $100 is L+100.
The following diagram illustrates Bill’s decision after the shock. The outcomes L, L+100 and L+250, and their respective values, are marked. The expected value of the gamble is L+125. The weighted value of the gamble is V(L+A).
Due to the convex curvature of the curve in the loss domain, Bill is risk seeking. As a result, the utility of the gamble is greater than the utility of the certain outcome. This can be seen in V(L+A) being greater than v(L+100).
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<--200#lossx2<--20#winev<--100#expected value of gamblexc<--120#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))+#Add labels L, v(L) and line to curve indicating eachannotate("text", x = x1, y =0, label ="L", size =4, hjust =0.5, vjust =-0.3)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(L)", size =4, hjust =-0.1, vjust =0.6)+#Add labels L+100, v(L+100) and line to curve indicating eachannotate("text", x = xc, y =0, label ="L+100", size =4, hjust =0.8, vjust =-0.3)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="v(L+100)", size =4, hjust =-0.1, vjust =0.3)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")+#Add labels 250+L, U(250+L) and line to curve indicating eachannotate("text", x = x2, y =0, label ="L+250", size =4, hjust =0.5, vjust =-0.3)+annotate("segment", x = x2, y =0, xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x2), xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x2), label ="v(L+250)", size =4, hjust =-0.1, vjust =0.45)+#Add labels L+E[A], v(A+L) and curve indicating eachannotate("text", x = ev, y =0, label ="L+E[A]", size =4, hjust =0.1, vjust =-0.3)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label ="V(L+A)", size =4, hjust =-0.1, vjust =0.45)
Figure 18.8: Bill’s consideration of gamble A and the $100 after the shock
18.2 Insurance
Summary
Classical economic theory explains insurance purchase through risk aversion, while prospect theory offers an alternative explanation involving risk-seeking behaviour in the loss domain and overweighting of small probabilities.
A risk-neutral agent would not purchase insurance due to its negative expected value, but a risk-averse agent with a logarithmic utility function may buy insurance due to diminishing marginal utility.
Prospect theory’s reflection effect suggests people are risk-seeking in the loss domain, which alone would predict that people wouldn’t buy insurance, as it involves choosing between a certain loss (premium) and a potentially larger loss.
Probability weighting in prospect theory suggests that people overweight small probabilities and underweight probabilities near certainty, which can make insurance attractive despite being in the loss domain.
The combination of a convex value function in the loss domain and overweighting of small probabilities can lead to insurance purchase under prospect theory, even when the reflection effect alone would suggest avoiding insurance.
18.2.1 Introduction
Insurance has a negative expected value due to the insurer’s profit and administrative costs. Why would a consumer purchase insurance?
The classical economic explanation for the purchase of insurance is based on diminishing marginal utility, which leads to risk aversion. Consumers are willing to buy insurance as the consumer prefers the certainty of the premium payment to the risk of suffering an uninsured loss.
Prospect theory provides an alternative explanation. The purchase of insurance involves a certain loss (the premium) or a gamble involving the possibility of either a large loss or the status quo. As prospect theory has people as risk seeking in the loss domain, we would not expect them to purchase insurance.
However, under prospect theory, people also overweight small probabilities. This overweighting of small probabilities can make the purchase of insurance attractive even though it is in the loss domain.
This combination of the loss domain with a small probability is the bottom-right quadrant of the fourfold pattern to risk attitudes generated by prospect theory. People tend to be risk averse in this circumstance.
Gains
Losses
High probability
Risk aversion
Risk seeking
Low probability
Risk seeking
Risk aversion
The following numerical example is an illustration.
An agent is considering insurance against bushfire for their house valued at H= $1 000 000. The house has a 1 in 1000 (p= 0.001) chance of burning down. An insurer is willing to offer full coverage for a premium (R) of $1100. (Note: $1000 is the actuarially fair price. The additional $100 might represent profit or administrative costs.)
18.2.2 Expected value
The first question I will consider is whether a risk-neutral person would purchase the insurance. A risk-neutral utility function is:
u(x)=x
A risk-neutral agent will choose the option with the highest expected value.
If the agent purchases insurance, they pay the premium and do not suffer any loss regardless of whether there is a bushfire or not. Therefore, the expected value of purchasing insurance is the loss of the premium:
The expected value of purchasing insurance is the guaranteed loss of the premium, $1100.
If the agent does not purchase insurance, they face the 1 in 1000 possibility of an uninsured loss. Therefore, the expected value of not purchasing insurance is the probability of loss times the value of the house:
The expected value of purchasing insurance is lower than the expected value of not purchasing insurance. Therefore, a risk-neutral agent would not purchase the insurance.
18.2.3 Expected utility
Would a risk-averse agent purchase the insurance? Suppose they have a logarithmic utility function (u(x)=\ln(x)) and they have $10 000 in cash in addition to their house, giving them wealth (W) of $1 010 000.
The logarithmic utility function has diminishing marginal utility. Diminishing marginal utility is the principle that the marginal utility from each additional unit decreases. In the context of wealth, this means that each additional dollar provides less satisfaction than the previous one.
Diminishing marginal utility means that the agent will be risk averse. They will prefer a certain outcome to a gamble with the same expected value.
To understand whether this risk-averse agent will purchase insurance in this instance, we need to compare the expected utility of purchasing insurance with the expected utility of not purchasing insurance.
The expected utility of purchasing insurance is the utility of the certain outcome, which is the utility of wealth after paying the premium:
The expected utility of not purchasing insurance is the probability-weighted sum of the utility of the two potential outcomes, the utility of wealth after losing the house and the utility of wealth if the house does not burn down:
The expected utility of purchasing insurance is greater than the expected utility of not purchasing insurance. This agent will purchase insurance.
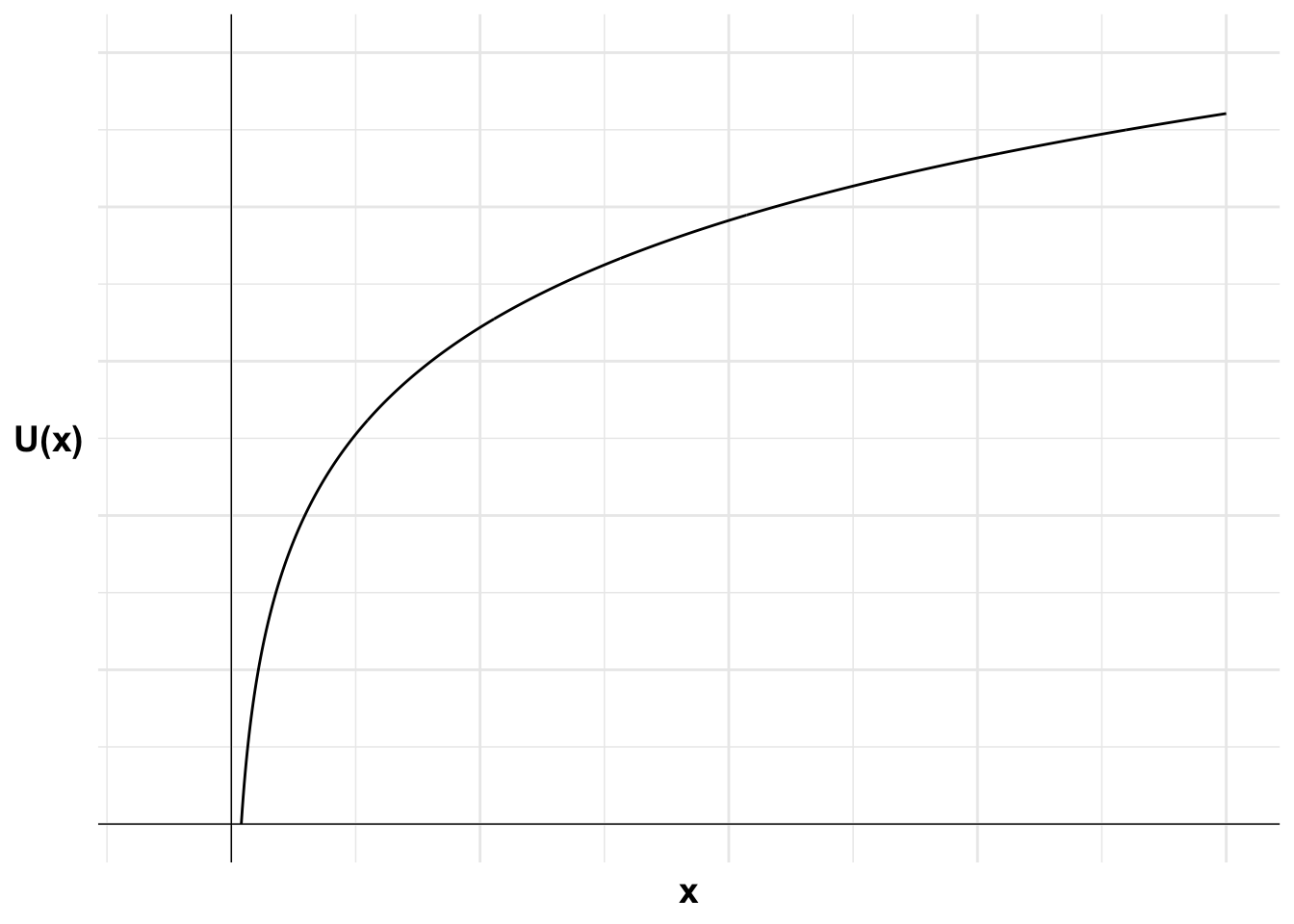
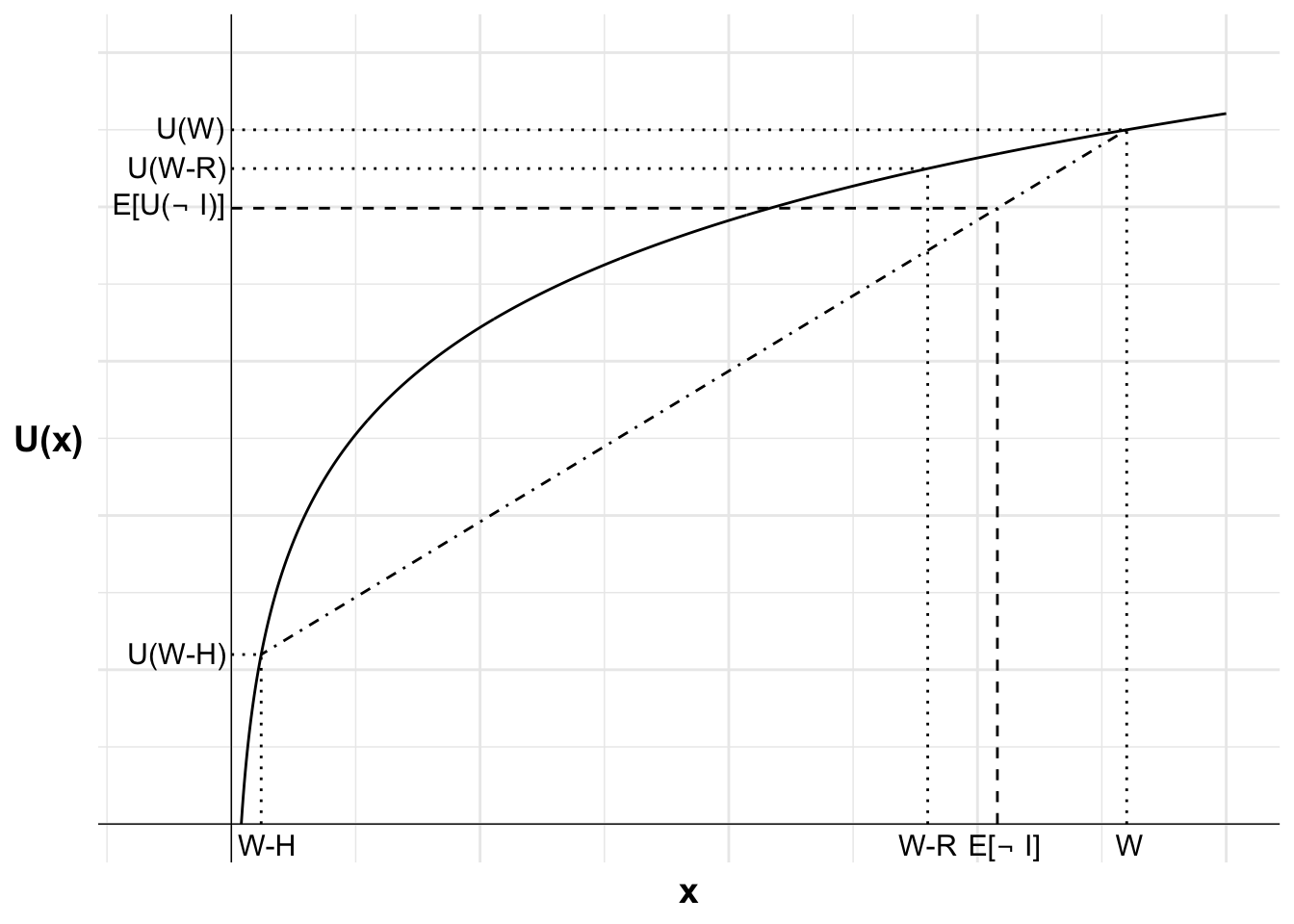
The following diagrams illustrate. First I plot the agent’s utility function. The utility function is concave as the agent is risk averse. Each additional unit of wealth provides less utility than the previous unit.
Code
library(ggplot2)library(latex2exp)u <-function(x){log(x)}df <-data.frame(x=seq(1,100,0.1),y=NA)df$y <-u(df$x)#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<-3#lossx2<-90#winev<-77#expected value of gamblexc<-70#certain outcomepx2<-(ev-x1)/(x2-x1)insurance_eu_1 <-ggplot(mapping =aes(x, y)) +geom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="U(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-8, 100), ylim =c(0, 5))insurance_eu_1
Figure 18.9: The utility function of a risk-averse agent
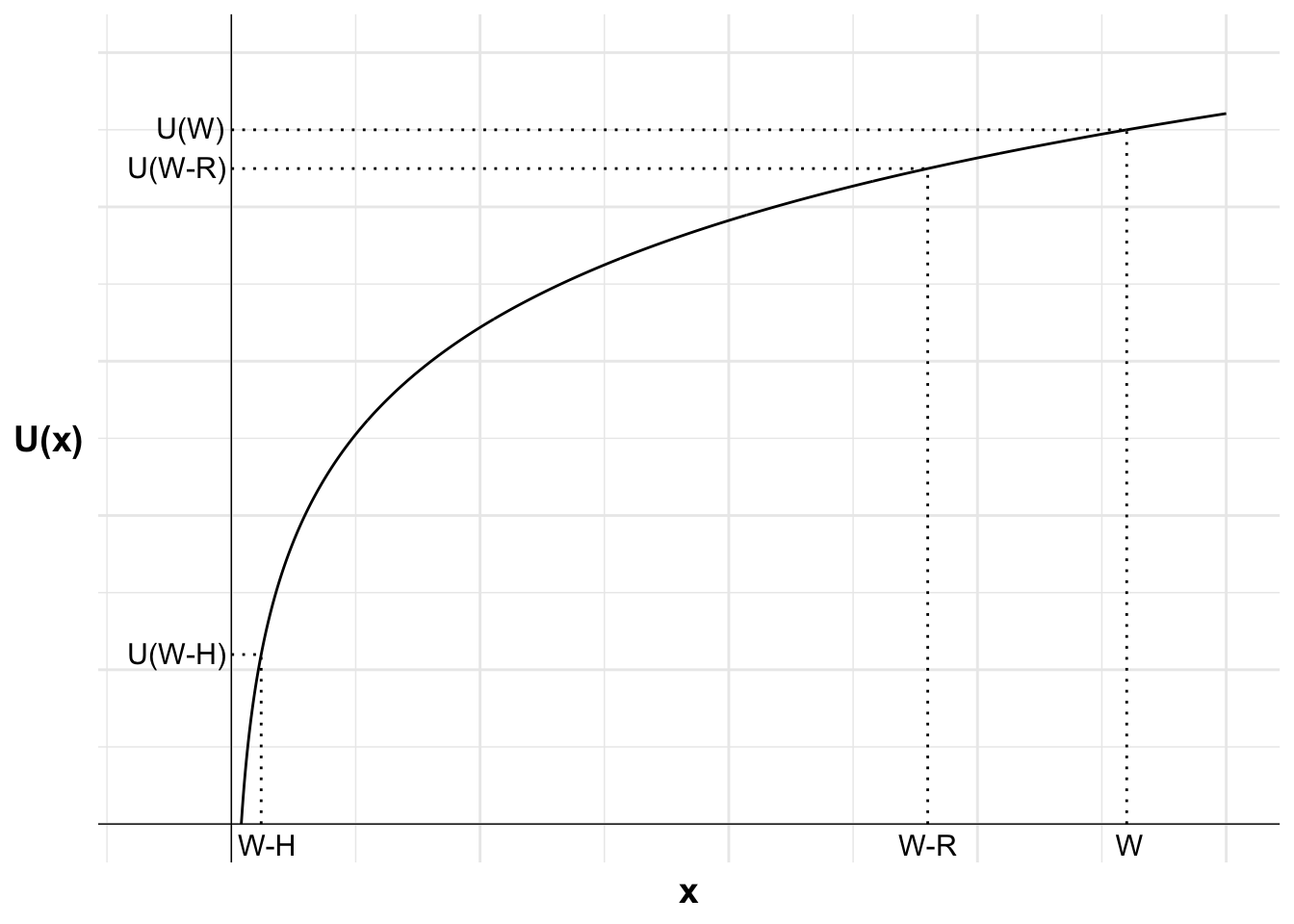
I then mark each possible outcome from purchasing or not purchasing insurance on the horizontal axis and the utility of each of those outcomes on the vertical axis. These are: wealth after losing the house when uninsured (W-H), wealth after paying the insurance premium (W-R), and wealth if uninsured but the house does not burn down (W). I have not drawn this to scale.
Code
library(ggplot2)library(latex2exp)u <-function(x){log(x)}df <-data.frame(x=seq(1,100,0.1),y=NA)df$y <-u(df$x)#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<-3#lossx2<-90#winev<-77#expected value of gamblexc<-70#certain outcomepx2<-(ev-x1)/(x2-x1)insurance_eu_2 <- insurance_eu_1 +#Add labels W, U(W) and line to curve indicating eachannotate("text", x = x2, y =0, label ="W", size =4, hjust =0.4, vjust =1.5)+annotate("segment", x = x2, y =0, xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x2), xend = x2, yend =u(x2), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x2), label ="U(W)", size =4, hjust =1.1, vjust =0.4)+#Add labels W-R, U(W_R) and line to curve indicating eachannotate("text", x = xc, y =0, label ="W-R", size =4, hjust =0.5, vjust =1.5)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="U(W-R)", size =4, hjust =1.05, vjust =0.45)+#Add labels W-H, U(W-H) and line to curve indicating eachannotate("text", x = x1, y =0, label ="W-H", size =4, hjust =0.4, vjust =1.5)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="U(W-H)", size =4, hjust =1.05, vjust =0.45)insurance_eu_2
Figure 18.10: The utility of the outcomes of purchasing insurance and not purchasing insurance
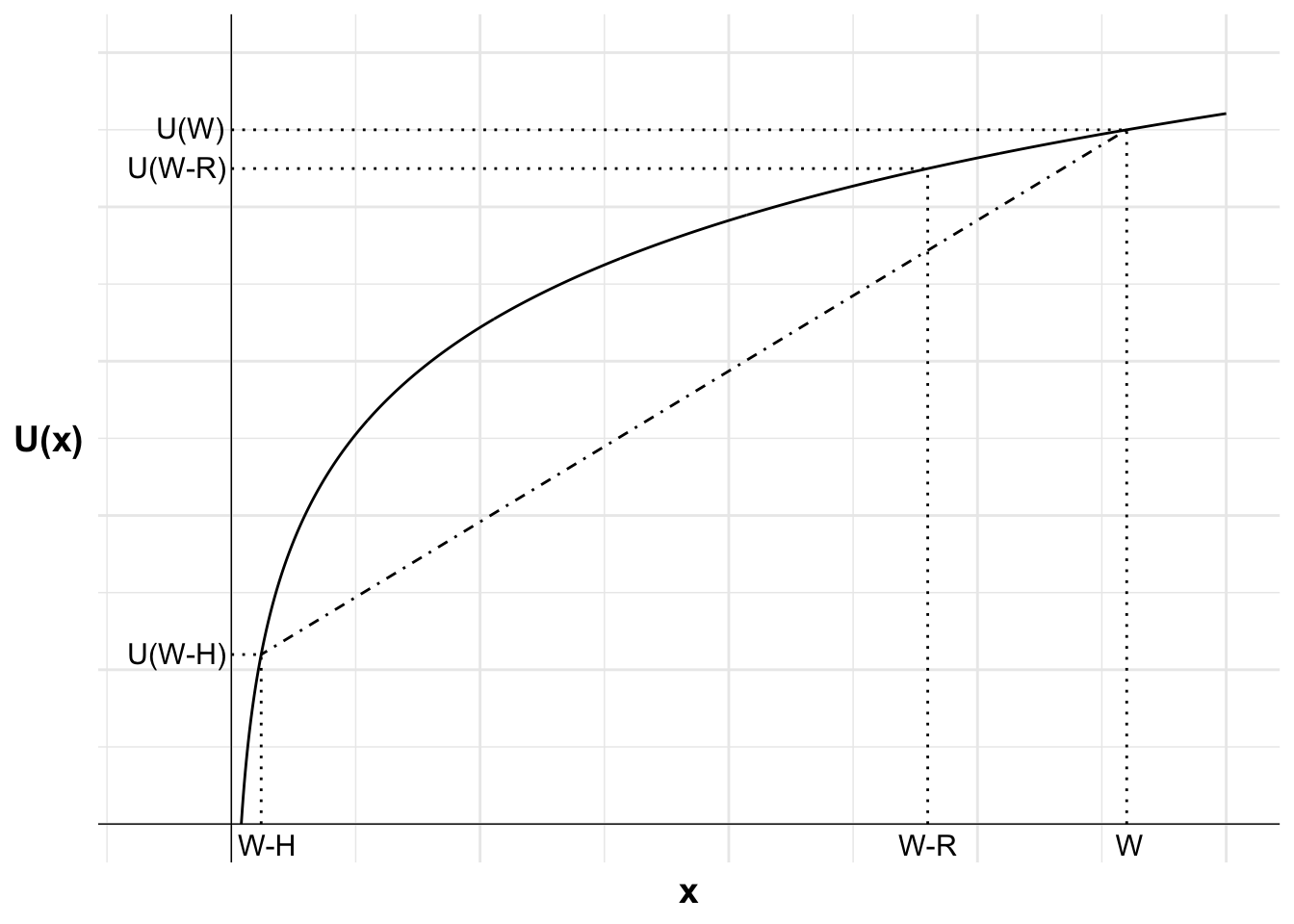
The expected utility of not purchasing insurance is the probability-weighted sum of the utility of the two potential outcomes, the utility of wealth after losing the house and the utility of wealth if the house does not burn down. I can show this on the diagram by plotting a dash-dot line between U(W-H) and U(W). The expected utility of not purchasing insurance will be on this line.
Code
library(ggplot2)library(latex2exp)u <-function(x){log(x)}df <-data.frame(x=seq(1,100,0.1),y=NA)df$y <-u(df$x)#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<-3#lossx2<-90#winev<-77#expected value of gamblexc<-70#certain outcomepx2<-(ev-x1)/(x2-x1)insurance_eu_3 <- insurance_eu_2 +#Add expected utility lineannotate("segment", x = x2, xend = x1, y =u(x2), yend =u(x1), linewidth =0.5, colour ="black", linetype="dotdash")insurance_eu_3
Figure 18.11: The expected utility line
The location of the expected utility is determined by the probability p of incurring a loss. This point lies at a distance of p from U(W) along the line (or equivalently, at a distance of 1-p from U(W-H)). This point aligns with the expected value of leaving the house uninsured \mathbb{E}[\neg \text{I}].
The utility of purchasing insurance, U(W-R), is greater than the expected utility of not purchasing insurance, \mathbb{E}[U(\neg \text{I})]. We can see this as U(W-R) is above \mathbb{E}[U(\neg \text{I})] on the diagram. This risk-averse agent will purchase insurance.
Code
library(ggplot2)library(latex2exp)u <-function(x){log(x)}df <-data.frame(x=seq(1,100,0.1),y=NA)df$y <-u(df$x)#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<-3#lossx2<-90#winev<-77#expected value of gamblexc<-70#certain outcomepx2<-(ev-x1)/(x2-x1)insurance_eu_4 <- insurance_eu_3 +#Add labels E[not I], E[U(not I)] and curve indicating eachannotate("text", x = ev, y =0, label =TeX("E[$\\neg$ I]", output='character'), parse=TRUE, size =4, hjust =0.4, vjust =1.4)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label =TeX("E[U($\\neg$ I)]", output='character'), parse=TRUE, size =4, hjust =1.05, vjust =0.45)insurance_eu_4
Figure 18.12: The expected utility of purchasing insurance and not purchasing insurance
18.2.4 The reflection effect
I will now move on to the elements of prospect theory, introducing them one at a time. The first element is the reflection effect.
Consider an agent who is risk seeking in the domain of losses but weights probability linearly. Their value function is:
v(x)=\left\{\begin{matrix}
x^{0.8} \qquad &\textrm{where} \space x \geq 0\\[6pt]
-2(-x)^{0.8} \quad &\textrm{where} \space x < 0
\end{matrix}\right.
x is the realised outcome relative to the reference point.
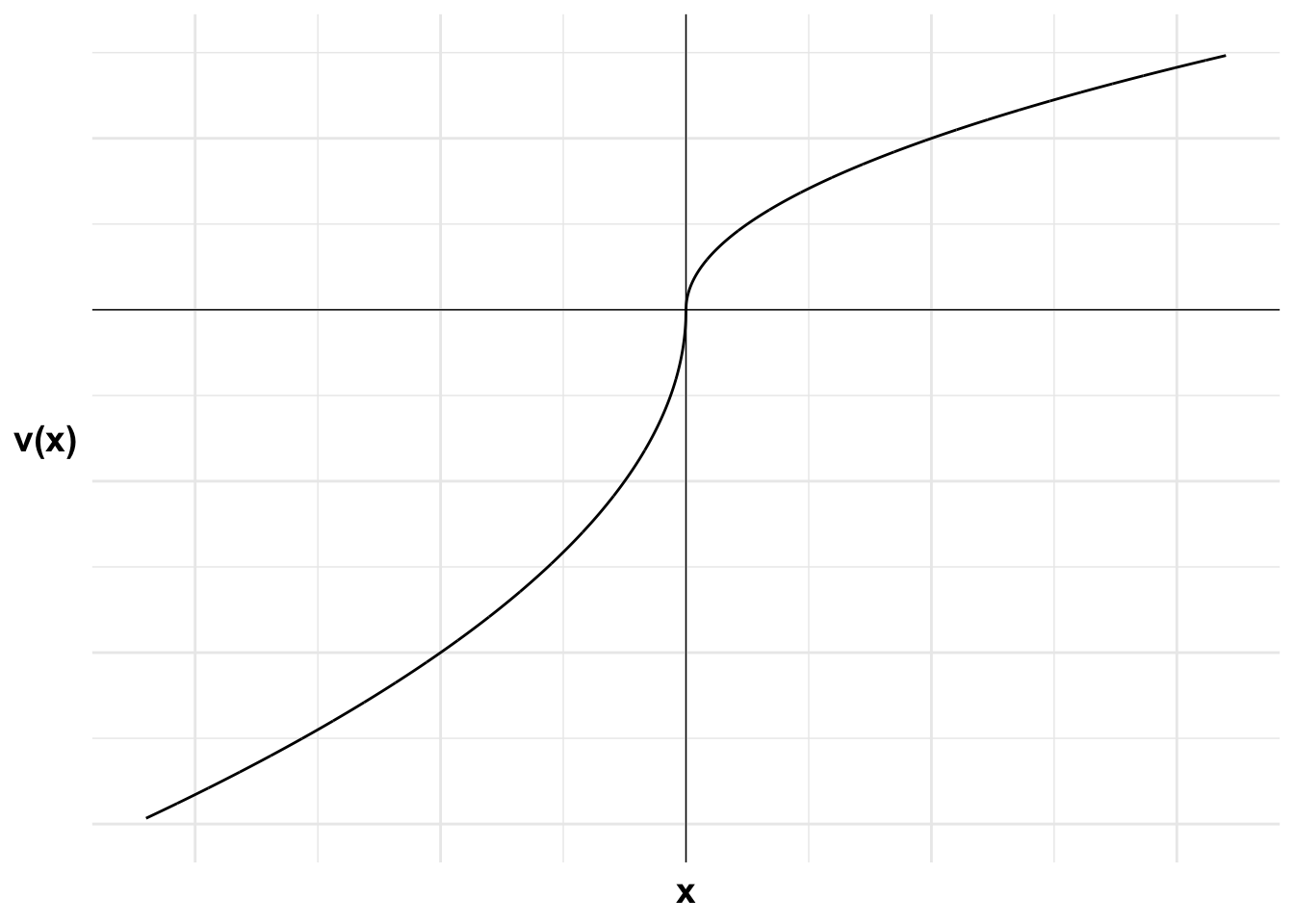
The reflection effect occurs as this value function is concave in the gain domain and convex in the loss domain. This leads to risk averse and risk seeking behaviour, respectively.
In this analysis, we will take the reference point as current wealth before the purchase of the insurance. Determination of the reference point can be arbitrary. What if you pay insurance every year? Would the reference point then be wealth minus the insurance payment, meaning the insurance payment is in the gain domain? In that case, the analysis changes.
We can see the outcomes for an agent with a reference point of wealth before purchasing insurance on the following line (not drawn to scale). The outcomes are the premium payment -R and the value of the house after a bushfire -H. If uninsured and no fire, the agent will remain at their reference point of the status quo.
Would this agent with the reflection effect and a reference point of wealth before purchasing the insurance make the purchase?
We need to compare the weighted value of purchasing insurance with the weighted value of not purchasing insurance. The agent will purchase insurance if the weighted value of purchasing insurance is greater.
The weighted value of purchasing insurance is the value of the certain outcome, which is the loss of the premium:
The weighted value of not purchasing insurance is the probability-weighted sum of the value of the two potential outcomes, the value of wealth after losing the house and the value of wealth if the house does not burn down:
As the value of purchasing insurance is less than the weighted value of not purchasing insurance, that is, V(\text{I})<V(\neg\text{I}), this agent does not purchase insurance. The diminishing feeling of loss leads to them weigh the certain loss of the premium relatively more heavily than the chance of losing the value of their house.
Including loss aversion in the value function does not change the decision as all possible outcomes are in the loss domain.
The following diagrams illustrate. First I plot the agent’s value function. The value function is concave in the gain domain and convex in the loss domain, leading to risk averse and risk-seeking behaviour, respectively. Each additional gain or loss of a unit of wealth relative to the reference point results in a smaller change in value than the previous unit. There is diminishing sensitivity to both gains and losses.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<--200#lossx2<-0#winev<--30#expected value of gamblexc<--60#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))
Figure 18.13: A value function with the reflection effect
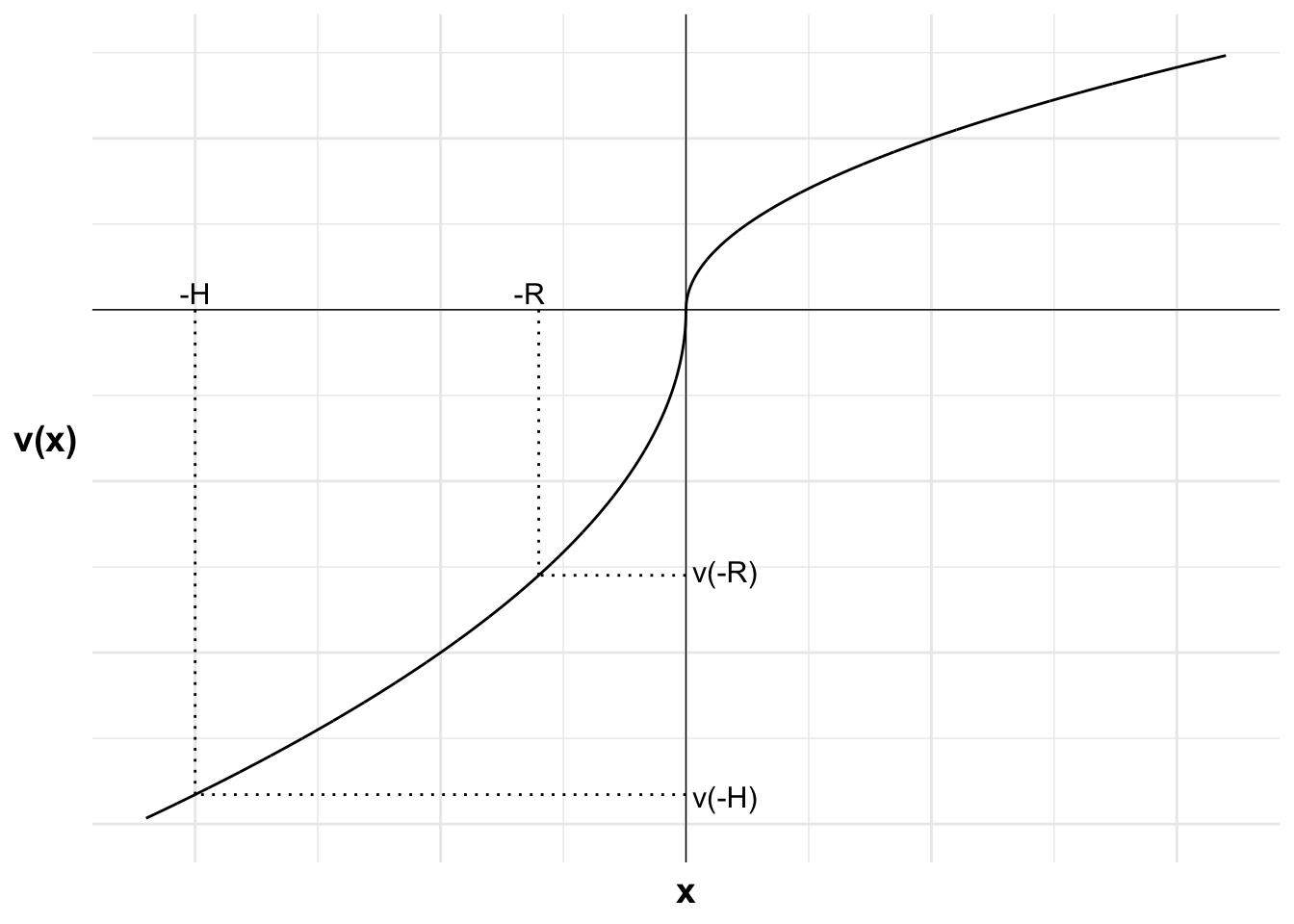
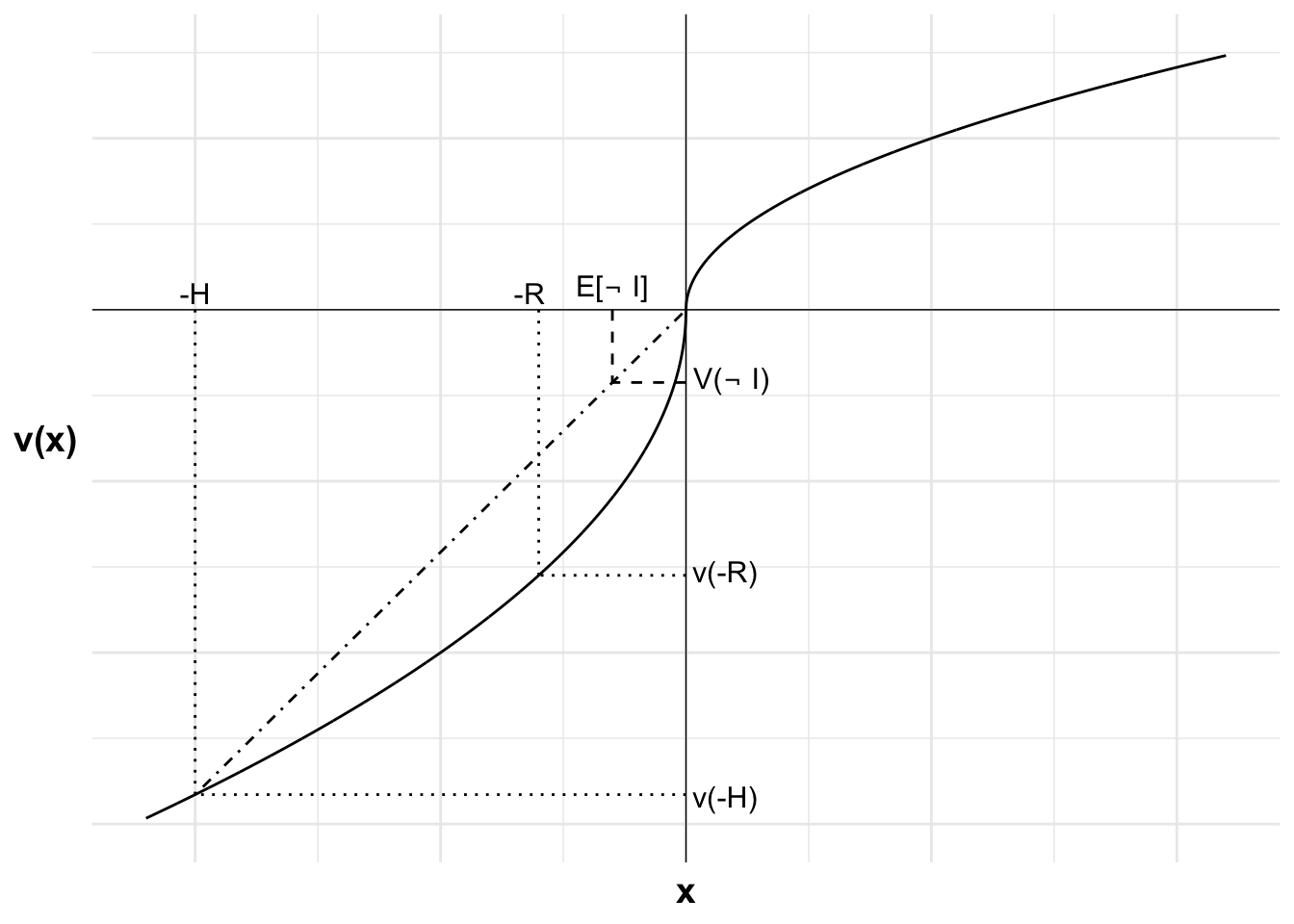
Each outcome and the value of that outcome from purchasing or not purchasing insurance is marked on the horizontal axis and the value of those outcomes on the vertical axis. These are: the premium payment -R and the outcome after a bushfire -H. If uninsured and no fire, the agent will remain at their reference point of the status quo.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<--200#lossx2<-0#winev<--30#expected value of gamblexc<--60#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))+#Add labels -H, v(L) and line to curve indicating eachannotate("text", x = x1, y =0, label ="-H", size =4, hjust =0.5, vjust =-0.3)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(-H)", size =4, hjust =-0.1, vjust =0.6)+#Add labels -R, v(-R) and line to curve indicating eachannotate("text", x = xc, y =0, label ="-R", size =4, hjust =0.8, vjust =-0.3)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="v(-R)", size =4, hjust =-0.1, vjust =0.3)
Figure 18.14: The value of the outcomes of purchasing insurance and not purchasing insurance
The weighted value of not purchasing insurance is the probability-weighted sum of the value of the two potential outcomes, the value of wealth after losing the house and the reference point. I can show this on the diagram by plotting a dash-dot line between v(-H) and v(0). The weighted value of not purchasing insurance will be on this line.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<--200#lossx2<-0#winev<--30#expected value of gamblexc<--60#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))+#Add labels -H, v(L) and line to curve indicating eachannotate("text", x = x1, y =0, label ="-H", size =4, hjust =0.5, vjust =-0.3)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(-H)", size =4, hjust =-0.1, vjust =0.6)+#Add labels -R, v(-R) and line to curve indicating eachannotate("text", x = xc, y =0, label ="-R", size =4, hjust =0.8, vjust =-0.3)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="v(-R)", size =4, hjust =-0.1, vjust =0.3)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")
Figure 18.15: The weighted value line
The location of this point is determined by the probability p of incurring a loss. This point lies at a distance of p from v(0) along the line (or equivalently, at a distance of 1-p from v(-H)). This point aligns with the expected value of leaving the house uninsured \mathbb{E}[\neg I].
The value of purchasing insurance, v(-R), is less than the weighted value of not purchasing insurance, V(\neg I). The agent will not purchase insurance. They are risk seeking in this loss domain.
Code
library(ggplot2)u <-function(x){ifelse (x >=0, x^0.5, -2*(-x)^0.5)}df <-data.frame(x =seq(-220, 220, 0.1),y =u(seq(-220, 220, 0.1)))#Variables for plot (may not match labels as not done to scale)#Payoffs from gamblex1<--200#lossx2<-0#winev<--30#expected value of gamblexc<--60#certain outcomepx2<-(ev-x1)/(x2-x1)ggplot(mapping =aes(x, y)) +#Plot the utility curvegeom_line(data = df) +geom_vline(xintercept =0, linewidth=0.25)+geom_hline(yintercept =0, linewidth=0.25)+labs(x ="x", y ="v(x)")+# Set the themetheme_minimal()+#remove numbers on each axistheme(axis.text.x =element_blank(),axis.text.y =element_blank(),axis.title=element_text(size=14,face="bold"),axis.title.y =element_text(angle=0, vjust=0.5))+#limit to y greater than zero and x greater than -8 (need -8 so space for y-axis labels)coord_cartesian(xlim =c(-220, 220), ylim =c(-30, 15))+#Add labels -H, v(L) and line to curve indicating eachannotate("text", x = x1, y =0, label ="-H", size =4, hjust =0.5, vjust =-0.3)+annotate("segment", x = x1, y =0, xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(x1), xend = x1, yend =u(x1), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(x1), label ="v(-H)", size =4, hjust =-0.1, vjust =0.6)+#Add labels -R, v(-R) and line to curve indicating eachannotate("text", x = xc, y =0, label ="-R", size =4, hjust =0.8, vjust =-0.3)+annotate("segment", x = xc, y =0, xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("segment", x =0, y =u(xc), xend = xc, yend =u(xc), linewidth =0.5, colour ="black", linetype="dotted")+annotate("text", x =0, y =u(xc), label ="v(-R)", size =4, hjust =-0.1, vjust =0.3)+#Add expected utility lineannotate("segment", x = x1, xend = x2, y =u(x1), yend =u(x2), linewidth =0.5, colour ="black", linetype="dotdash")+#Add labels E[\neg I], V(\neg I) and curve indicating eachannotate("text", x = ev, y =0, label =as.character(TeX("E[$\\neg$ I]")), size =4, hjust =0.5, vjust =-0.3, parse=TRUE)+annotate("segment", x = ev, y =0, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("segment", x =0, y =u(x1)+(u(x2)-u(x1))*px2, xend = ev, yend =u(x1)+(u(x2)-u(x1))*px2, linewidth =0.5, colour ="black", linetype="dashed")+annotate("text", x =0, y =u(x1)+(u(x2)-u(x1))*px2, label =as.character(TeX("V($\\neg$ I)")), size =4, hjust =-0.1, vjust =0.45, parse=TRUE)
Figure 18.16: The reflection effect and insurance
18.2.5 Probability weighting
Would a person who is risk seeking in the domain of losses (that is, a person with a value function with reflection effect discussed earlier) who weights probability in accordance with prospect theory purchase the insurance?
Prospect theory proposes that people overweight small probabilities. They might weight probabilities as per the following table:
Probability(p)
0.001
0.01
0.1
0.25
0.5
0.75
0.9
0.99
0.999
Weight\pi(p)
0.01
0.05
0.15
0.3
0.5
0.7
0.85
0.95
0.99
That is, an outcome with a probability of p=0.001 is given a weight \pi(p) of 0.01, ten times what its probability would suggest. An outcome with a probability of p=0.01 is given a weight \pi(p) of 0.05, five times the weight.
Similarly, a probability of p=0.99 is given a weight \pi(p) of 0.95 and a probability of p=0.999 is given a weight \pi(p) of 0.99, implying that probabilities near certainty are underweighted relative to certainty itself.
To assess whether this person will purchase insurance, we need to compare the weighted value of purchasing insurance with the weighted value of not purchasing insurance. They will purchase insurance if the weighted value of purchasing insurance is greater.
The weighted value of purchasing insurance is the value of the certain outcome, which is the loss of the premium:
As the value of purchasing insurance is greater than the value of not purchasing insurance, that is, V(\text{I})>V(\neg\text{I}), this person purchases insurance.
Although the diminishing feeling of loss leads to them weigh the certain loss of the premium relatively more heavily than the chance of losing the value of their house, the overweighting of the probability of fire leads them to purchase insurance. Again, if we had included loss aversion, it would not have changed the decision, as all possible outcomes are in the loss domain.
18.3 A multi-bet
A multi-bet allows a gambler to combine a series of individual bets into a single wager, with the odds of all the single bets multiplied to achieve the final payoff. The gambler only wins the wager if all of the single bets are successful. Or in other words, if a single bet is lost, the entire multi-bet is lost. A multi-bet is also known as an “accumulator” bet or “parlay”.
For example, a multi-bet might combine the following bets:
GWS Giants to defeat Adelaide Crows: $1.65 (that is, $1.65 is paid out for each $1 bet)
Fremantle Dockers to defeat Sydney Swans: $2.10
Essendon Bombers to defeat Geelong Cats: $3.50
North Melbourne Kangaroos to defeat Melbourne Demons: $4.00
West Coast Eagles to defeat Brisbane Lions: $6.00
If all five bets are successful, the gambler would win $291 for every $1 they have bet. (That is 1.65 x 2.10 x 3.50 x 4 x 6 = 291.06). If any of GWS, Fremantle, Essendon, North Melbourne, or the West Coast Eagles lose, the bet is lost.
Many bookmakers also offer a “cash out” option for multi-bets. If the bet has been successful up to the date of the “cash out”, a gambler can “cash out” their bet before the remaining games are complete at a price offered by the bookmaker. The “cash out” offers are typically unattractive relative to the expected value of seeing out the rest of the multi-bet.
For example, Betty places a $20 multi-bet involving all nine games of Australian Rules Football one weekend. After eight games, she has picked all eight winners. If Geelong defeats North Melbourne in the ninth game she will win $10,000. Geelong is a heavy favourite, with a 95% probability of winning.
Betty checks the cash out price for the multi-bet and sees that she can cash out the bet now for $7,000, a great return on her initial $20. That return, however, is much below the expected value of seeing the multi-bet through to the end ($9,500).
Betty makes decisions according to prospect theory. That is, she judges gains and losses relative to a reference point, is loss averse, and has diminishing sensitivity to gains and losses in both directions. She also overweights certainty (which is equivalent to overweighting small probabilities).
What elements of prospect theory might lead Betty to cash out the bet before the final game?
We can consider multiple potential reference points Betty might use to make her decision.
One potential reference point is Betty’s position before making the bet. In that case, Betty is comparing:
a certain gain of $6980 and
a gamble with a loss of $20 and a gain of $9,980.
The gamble is largely in the gain domain in which Betty is risk averse. Her risk aversion may lead her to cash out rather than take the gamble. The potential $20 loss may be overweighted due to loss aversion, but it is a relatively insignificant sum.
Another potential reference point is Betty’s position immediately after making the bet. She has adapted to the payment of $20. Here the analysis is similar. Betty is comparing:
a certain gain of $7000 and
a gamble with a gain of $10,000 or a payment of zero
The gamble is completely in the gain domain, where Betty is risk averse. Her risk aversion may lead her to cash out rather than gamble. Loss aversion is irrelevant in this instance.
Another potential reference point is that Betty is taking the $7000 to be locked in. This means she is comparing:
staying at the status quo with certainty and
a gamble involving a potential loss of $7000 and a gain of $3,000.
In this case, the combination of risk aversion reducing the value of the gain and loss aversion increasing the relative magnitude of the pain of loss could lead her to cash out. This would be counteracted by the convex curvature in the loss domain, but the loss aversion effect would likely dominate.
Finally, Betty’s weighting of probabilities will also affect her decision. Overweighting certainty means overweighting small probabilities, such as the small probability of Geelong losing. This overweighting would push her towards cashing out as the loss would have greater weight in her calculation of the weighted value of each option.